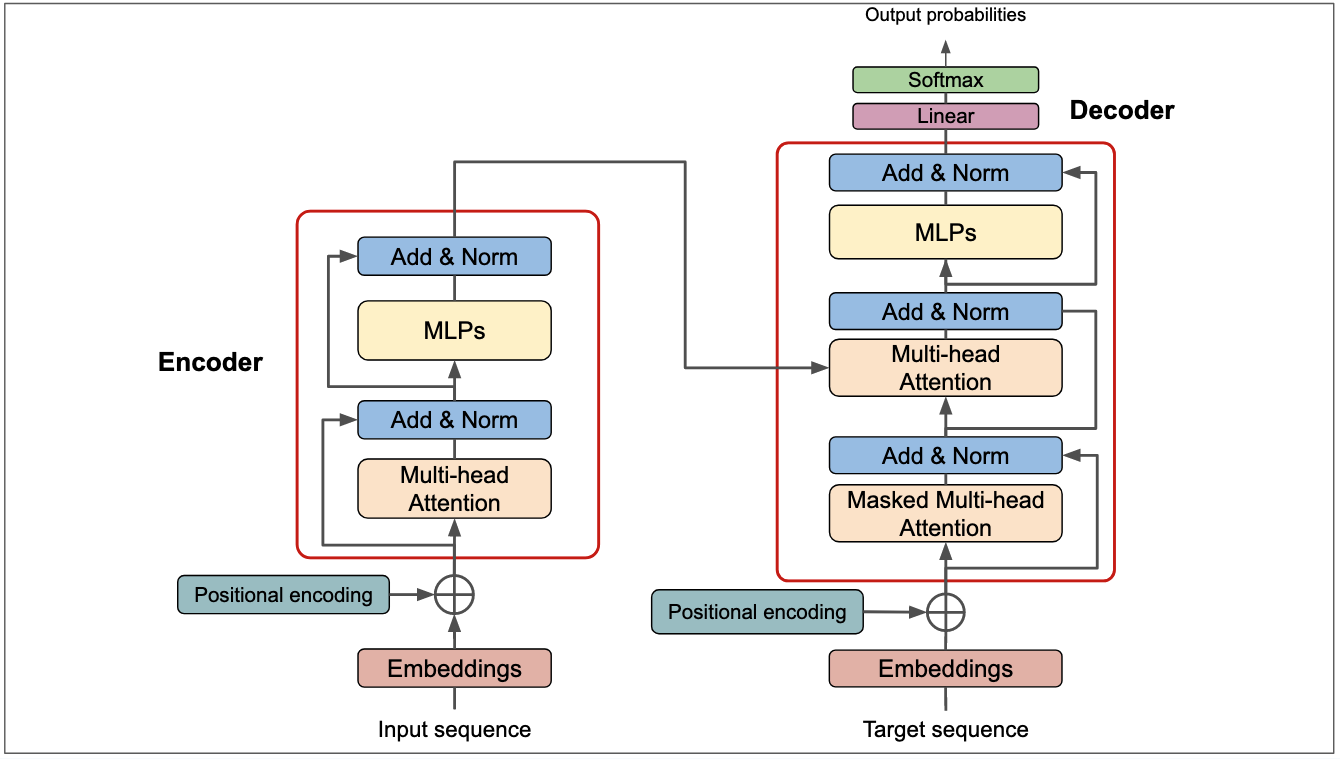
写在开始之前:本笔记内容是基于西北工业大学2026春季学期本科模式识别与机器学习内容以及全班同学的笔记内容整理而成,在此感谢主讲老师朱老师以及各位助教的辛苦付出,也感谢各位同学帮助我整理这份笔记!
机器学习的核心目标,是从数据中学习到输入到输出的映射规律,从而实现对未知数据的预测与决策。机器学习的本质是寻找最优预测函数的过程:预测函数 f 接收输入 x,并产生对应的输出 y,即 y = f(x)。我们的目标是在所有可能的函数中,找到最贴合数据规律的最优映射关系。
1. 机器学习基本定义与损失函数
- 机器学习的核心定义(函数族与参数空间)
- 损失函数与最优参数的数学表达
- 均方误差(MSE)
2. 信息熵、交叉熵与 KL 散度
- 自信息(Self-information)
- 信息熵(Shannon Entropy)
- 交叉熵(Cross-Entropy)
- KL 散度(Kullback-Leibler Divergence)
- 熵、交叉熵、KL 散度的核心关系
3. NumPy 核心原理与应用
- NumPy 的核心对象:ndarray 与 ufunc
- 机器学习中使用 NumPy 的原因(运算性能、内存管理、线性代数、向量化编程等)
4. SIMD 原理与 GPU 并行计算的对比分析
- SIMD 加速计算的原理(数据级并行、向量寄存器)
- SIMD 的主要限制
- SIMD 与 GPU 并行计算(SIMT)的区别
- 机器学习中依赖 SIMD 的操作
5. Pandas 数据处理与分析
- Series 和 DataFrame 的数据结构
- Pandas 在机器学习中的作用(数据选择、脏数据处理、DataFrame 到张量转换)
6. 极大似然估计(Maximum Likelihood Estimation, MLE)
- 似然函数、对数似然与最优参数求解
- 抛硬币问题示例
- MLE 与损失函数的关系(MSE 与交叉熵的推导)
- 极大似然估计的局限性
笔记一.pdf