在机器学习任务中,我们通常将原始数据集划分为三个互斥的部分:训练集、验证集和测试集。这种划分是评估模型泛化能力、防止过拟合的基础。同时,偏差与方差的权衡贯穿模型选择与评估的始终,是理解模型行为、指导改进方向的核心视角。
1. 数据集划分与模型拟合理论
- 训练集、验证集、测试集的定义与功能
- 常见划分比例与 K 折交叉验证
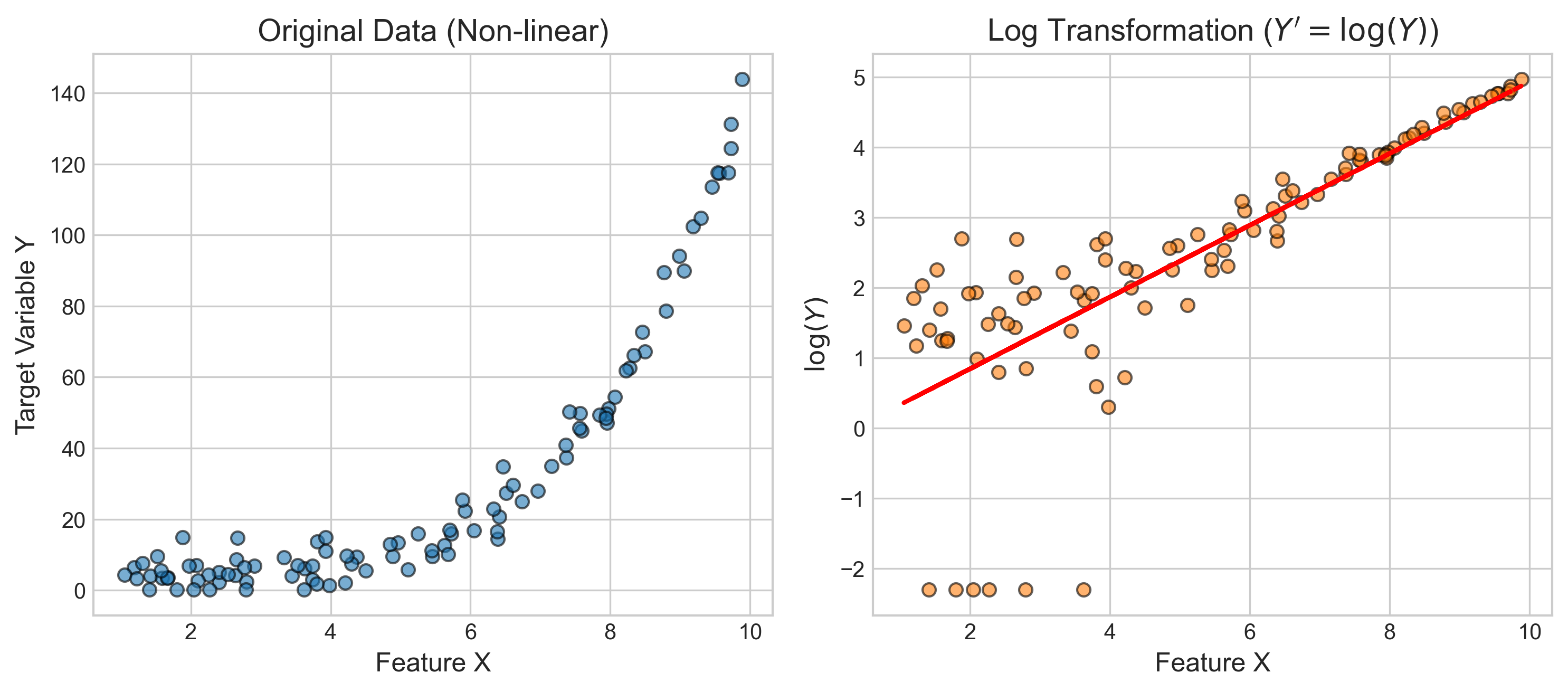
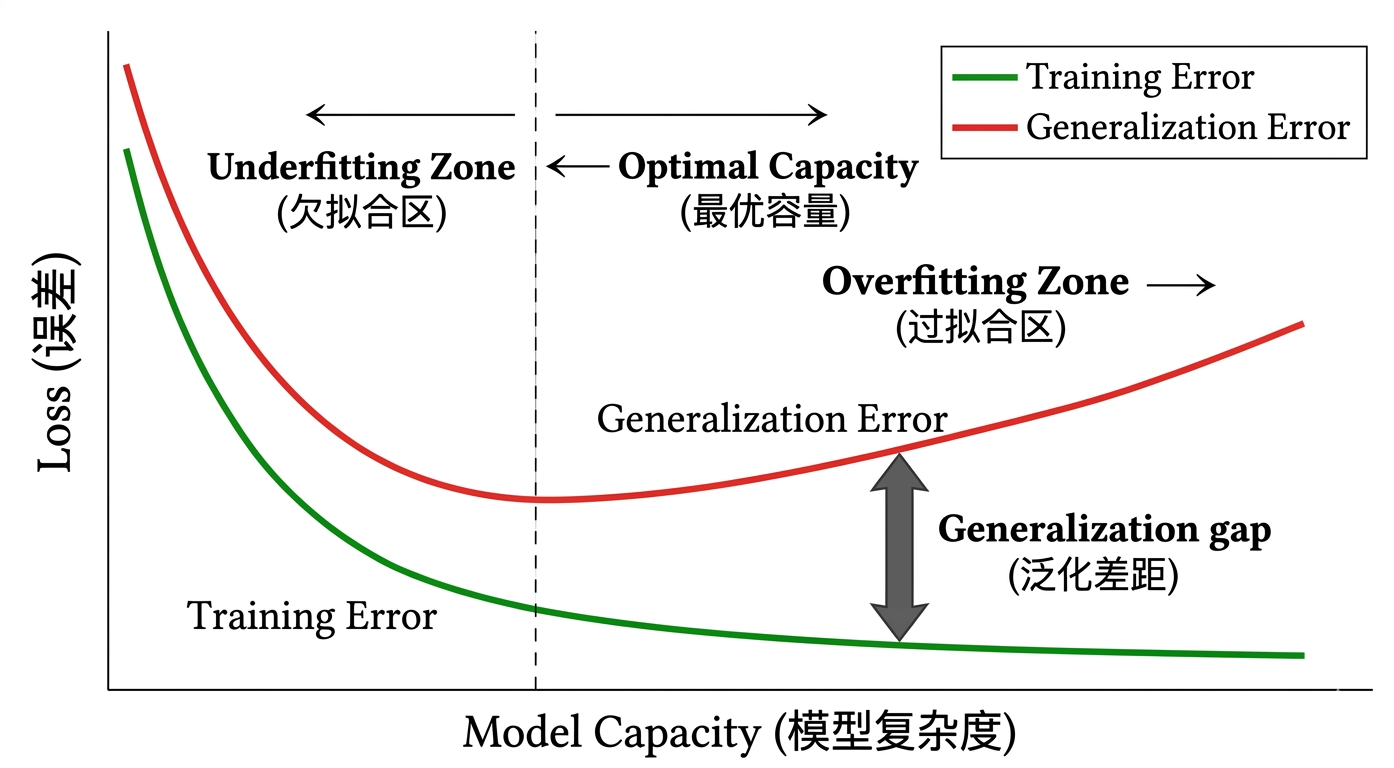
- 欠拟合与过拟合的基本定义
- 模型容量与误差曲线
- 偏差-方差权衡(Bias-Variance Tradeoff)
2. 机器学习流水线
- 机器学习流水线全流程详解
- 第一阶段:数据准备(收集→清洗→特征工程→划分)
- 第二阶段:模型构建(创建→训练→验证→优化→最终模型)
- 第三阶段:模型应用(部署与监控)
3. 过拟合与欠拟合及其缓解方法
- 过拟合的定义与处理方法(数据增强、降维、正则化/L1/L2/弹性网络、早停、集成学习)
- 欠拟合的定义与处理方法(添加特征、增加复杂度、减小正则化)
4. 偏差与方差
- 泛化误差的偏差-方差分解
- 偏差-方差权衡
5. 交叉验证:K-Fold 数据集划分方法
- 方法简介与基本步骤
- K 值的选取策略
6. 回归问题的评价指标
- 基于误差的指标:MSE、RMSE、MAE
- 拟合优度指标:决定系数 R²(基本公式、统计学含义、调整 R²)
- 指标选择指南
7. 分类问题评价指标
- 混淆矩阵
- 准确率、精确率、召回率、F1 分数
- 阈值对 Precision 与 Recall 的权衡
- 多分类问题中的宏平均与微平均
8. ROC 曲线与 AUC 指标
- ROC 曲线的绘制(TPR、FPR)
- AUC 的定义与直观理解
- AUC 的概率学本质
- AUC 的三种计算方法(梯形面积法、Wilcoxon-Mann-Whitney Test、正样本 Rank 法)
- ROC 与 PR 曲线的区别
9. 不平衡数据处理
- 数据不平衡的定义、量化指标与致命影响
- 常用方法:欠采样、过采样、SMOTE、代价敏感学习
- 实践选择指南
10. Focal Loss
- 从二分类交叉熵到 Focal Loss 的定义
- 核心机制:重新分配训练注意力
- γ 参数的作用
- 难学样本与噪声样本的区分
- 延伸变体与最新研究方向(QFL/GFL、DFL、GFLV2、Varifocal Loss、EFL)
笔记五.pdf