数据准备通常可以分为四个紧密衔接的部分:数据收集、数据清洗、特征工程和数据集划分。它们在实际项目中往往相互影响、反复迭代,共同决定模型能否被有效训练。特征工程则是把原始数据转化成更适合学习任务的特征表达,在传统机器学习中,其质量往往比模型选择更能决定最终效果。
1. 机器学习数据准备
- 数据准备的四大部分:数据收集、数据清洗、特征工程、数据集划分
- 数据清洗的定义与一般流程(数据理解→质量检查→缺失处理→异常处理→去重→标准化→输出)
- 数据准备的简化案例:从学生成绩表到可训练数据
2. 特征工程基础
- 特征质量评估:有信息、少噪声、符合模型假设
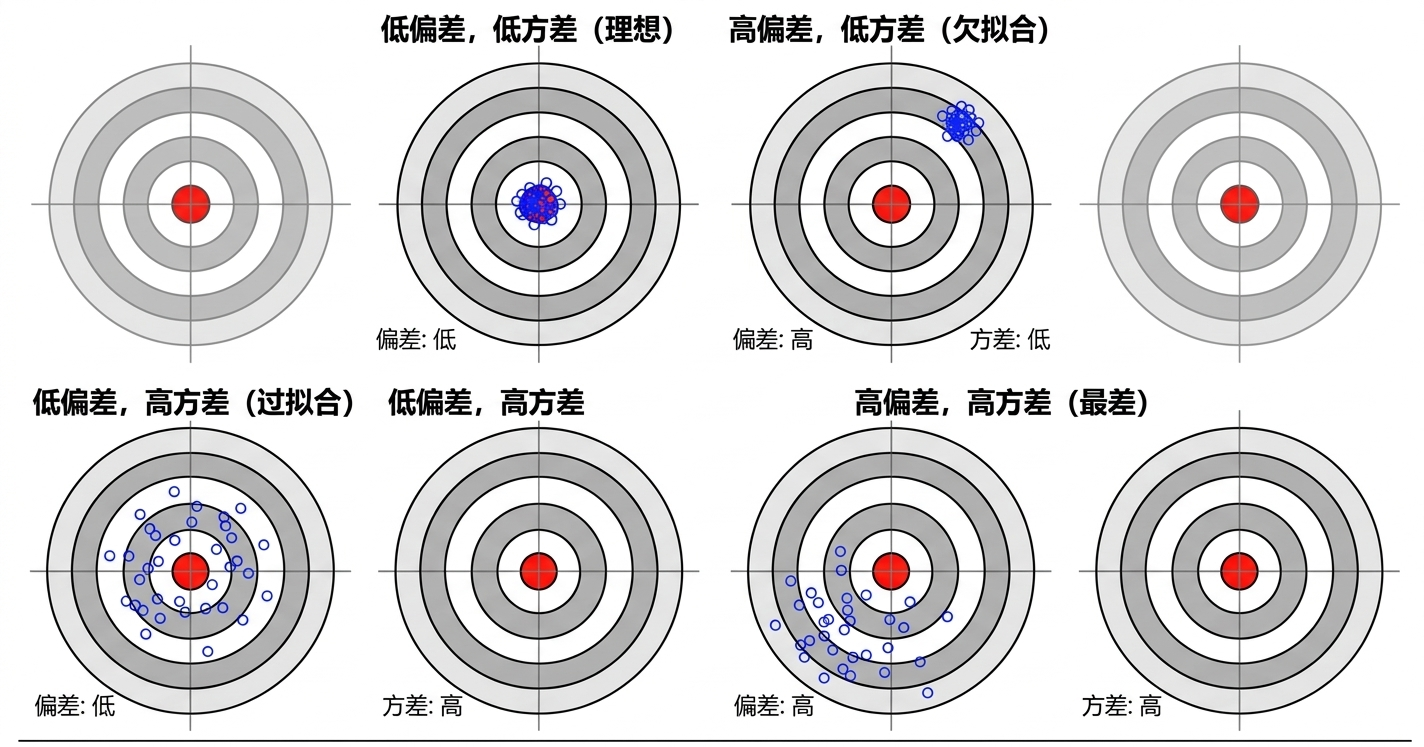
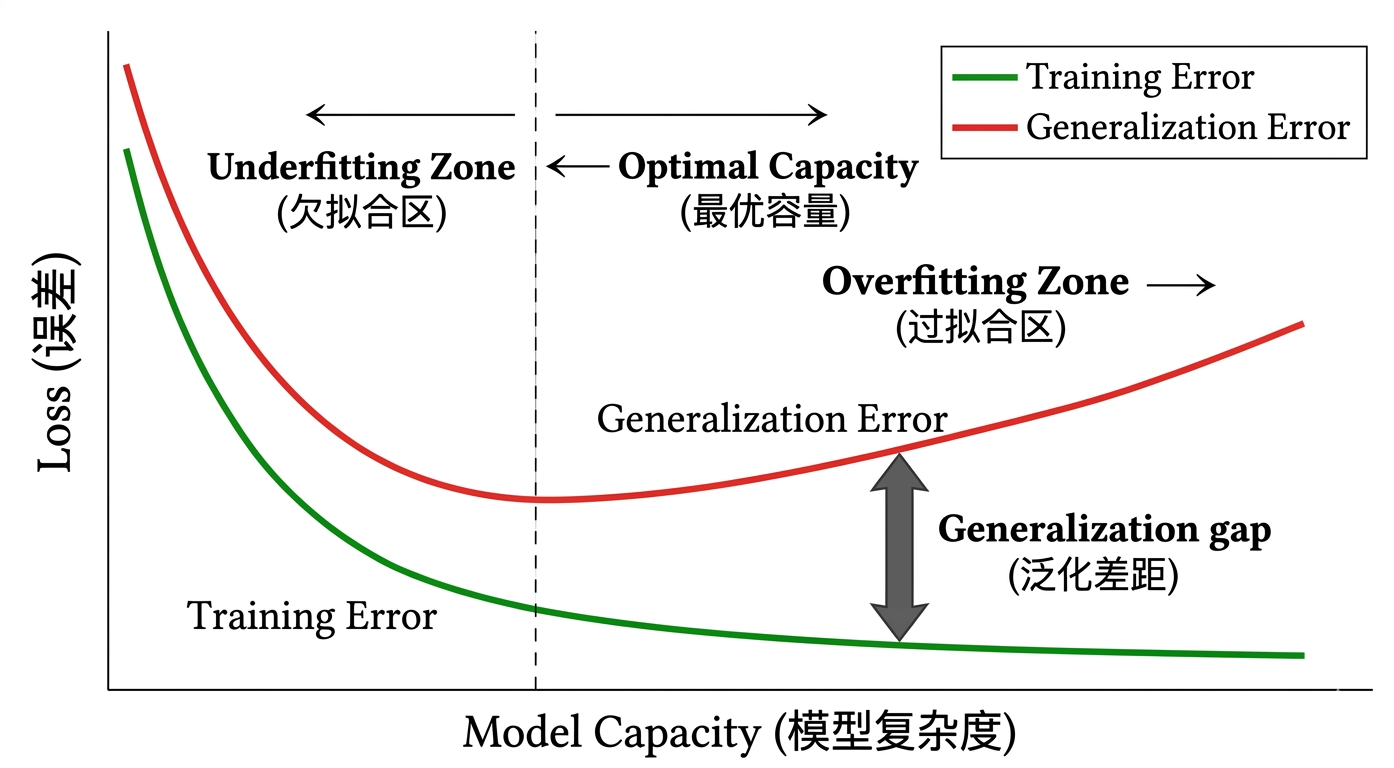
- 特征数量权衡:欠拟合风险 vs 过拟合与维度灾难
- 特征工程对模型的作用(提升信噪比、赋予非线性能力、优化数值稳定性、语义对齐)
- 特征工程的标准执行流程(数据理解→特征构造→特征变换→特征选择→特征评估)
- 特征构建案例:游戏商城皮肤购买预测
3. 特征构建与编码
- 特征构建概述(从原始数据到数值向量)
- Echo Nest 音乐推荐系统的特征构建实例
- 隐式反馈量化与对数缩放
- 余弦相似度计算
- One-Hot 编码:基本概念、为什么不用直接编号、优点、缺点
4. 特征变换与规范化
- 归一化(Min-Max Normalization)及其鲁棒性问题
- Z-Score 标准化(Standardization)及形态保留特性
- 数据规范化的模型适用性边界(梯度类模型必须规范化,树模型无需规范化)
- 分箱法/离散化:等宽分箱、等频分箱、自定义分箱
- 分箱后处理与编码(序号编码、One-Hot 编码、均值编码)
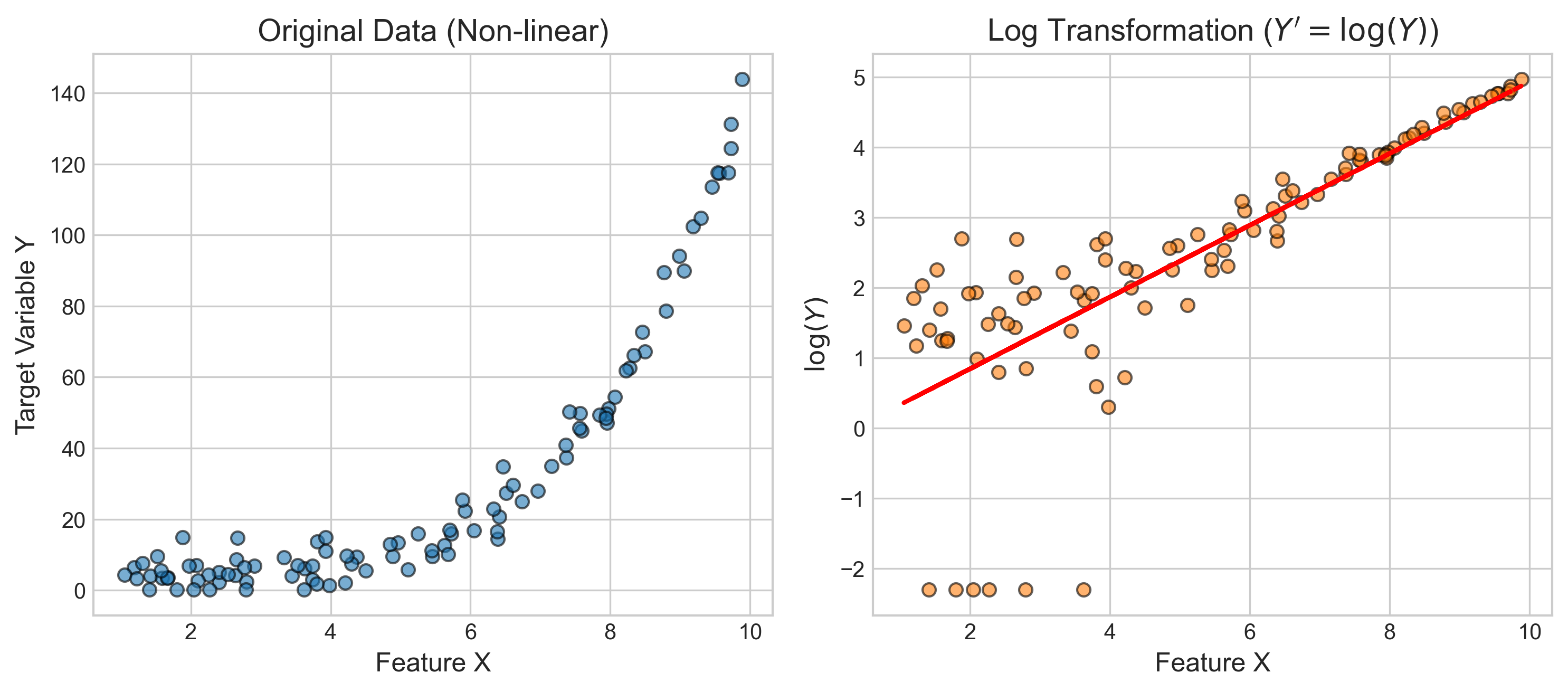
- 转换特征构造:单变量变换、多项式特征、组合特征、比率与差值
- 特征变换的深层原理(条件数优化、数值稳定性、正则化公平性)
5. 聚合特征构造
- 定义与核心数学表达(均值、方差、极值、频数)
- 时间窗口聚合
- 电商场景聚合特征构造示例
- 实战流程与注意事项
6. 特征提取与特征选择
- 降维问题的背景(计算复杂度、维数灾难)
- 特征提取 vs 特征选择的核心对比
- 常用特征提取方法(PCA、LDA、SIFT、Word2Vec)
- 特征选择的三大策略:Filter、Wrapper、Embedded
- 模型性能与计算复杂度的权衡
笔记四.pdf